
Randomize, Identify, or Dream
Wednesday, June 3, 2026 · Learning

A robot policy trained inside a simulator on a Unitree G1 humanoid does not know that the bushing on the real robot’s left ankle has lost two-tenths of a millimeter to wear after twelve hundred hours of operation. The classical answer is to randomize: train under a simulator that wobbles its own physics enough that the worn-bushing condition is one sample inside the training distribution. The policy never learns to depend on any particular value of friction or mass, so when reality hands it a slightly off value, it treats the difference as another draw from the training set. This is the trick that has carried robot learning since 2017, and in 2026 it is in the middle of a three-layer upgrade. Last issue showed that policies have a data-scaling law to lean on. The question today is where the rest of the gap gets closed.

Three mechanisms are converging in the production stack. Randomize the broad envelope. Identify the actual parameters from a short window of real-robot data. And, for the part of the gap physics engines get visibly wrong, drop the physics engine and let a neural simulator hallucinate the next frame from 44,000 hours of human video.
How it actually works
Domain randomization is the lazy theorem. You list the parts of your simulator you do not trust, friction at every joint, the exact mass of every link, motor torque constants, sensor noise floors, lighting, camera angles, and sample them from a wide enough distribution that reality lands inside the spread. The policy learns the behavior that survives this variation. On a real robot, the real parameter vector is just one more draw from the training distribution. The argument is not that the policy figures out the parameters, only that it never relied on them. NVIDIA’s Isaac Lab 2.3, released in November 2025, packages this as a configuration object you attach to any training environment. You can spin up thousands of parallel simulated robots on a single GPU, each one with a slightly different friction profile, payload mass, motor gain, and camera setup.

Randomization is a blunt instrument. Every dimension of variation the policy has to absorb is paid for in peak performance, the way an athlete who trains in mountains, oceans, and deserts is worse on any one terrain than a local specialist. So in 2026 the second layer is system identification, the targeted fix. Run the candidate policy on the real robot for a few minutes, collect (state, action, next-state) samples, and tune the simulator’s parameters so its predictions match reality. SPI-Active, a 2025 paper from Carnegie Mellon and NVIDIA, treats this as an active exploration problem. The robot deliberately probes the corners of state space where simulator predictions diverge most from reality. The reported gain is 42 to 63 percent lower locomotion error than passive identification, validated on the Unitree Go2 and G1.

The newer cross-cutting trick is to treat the simulator itself as a randomization knob. PolySim, an October 2025 paper, trains a humanoid policy across multiple physics engines in parallel: MuJoCo, Isaac Gym, Genesis, and Brax run alongside each other and disagree about contact, friction, and articulation in different ways. The policy that survives the disagreement gap deploys zero-shot on the real Unitree G1, no real-robot fine-tuning required. Any one simulator is wrong in known ways, but the agreement set across four of them is closer to physics than any one on its own.
The visual half of the gap closes through a different route. The 2024 answer was photorealistic rendering plus random texture, lighting, and pose. The 2026 answer is Gaussian Splatting, a way of reconstructing a real scene out of millions of fuzzy 3D blobs that render in real time. SplatSim swaps the meshes inside a physics simulator for splat reconstructions of real scenes and reports 86 percent zero-shot transfer. RoboSplat reports 88 percent one-shot transfer from a single real demonstration, beating prior baselines that required hundreds.
The largest question of all is whether you need a physics engine at all. NVIDIA’s DreamDojo, released in February 2026, is a world model trained on roughly 45,000 hours of egocentric human video. Give it an action signal and it decodes the next RGB frame plus sensor state directly in pixel space. There is no MuJoCo running underneath it, no rigid-body solver, no graphics engine. The reported correlation between DreamDojo’s simulated success rate and real-world success rate is 0.995 on a fruit-packing benchmark. The distilled real-time version runs at almost eleven frames per second. NVIDIA’s framing is that the parameterized domain-randomization stack is “Simulation 1.0” and DreamDojo is “Simulation 2.0,” where the simulator’s job is not to enforce Newton’s laws but to imagine the next physically-plausible frame, learned from data.
New this week
DreamDojo (NVIDIA, February 6, 2026, accepted to ICML 2026) is the open-source release that turns the neural-simulator thesis from internal NVIDIA framing into a benchmark other labs can replicate or refute. The 0.995 correlation is the headline, but the more useful claim is that mental rehearsal inside DreamDojo before acting picks up 17 percent in real-world success out of the box.
PolySim (October 2025) is the multi-simulator randomization paper most likely to enter production stacks this year. Cheaper to deploy than DreamDojo, no neural-rendering pipeline required, zero-shot on the real Unitree G1.
Cosmos-Transfer2.5, announced at NVIDIA GTC 2026 in March, is the bridge between physics-engine simulators and neural-renderer worlds. It takes a synthetic frame from Isaac Sim and translates it into a photorealistic variant matching a target real environment, the way a style-transfer model paints one image in the style of another. 1X uses it on NEO Gamma. Skild AI uses it for synthetic training sets.
What to notice
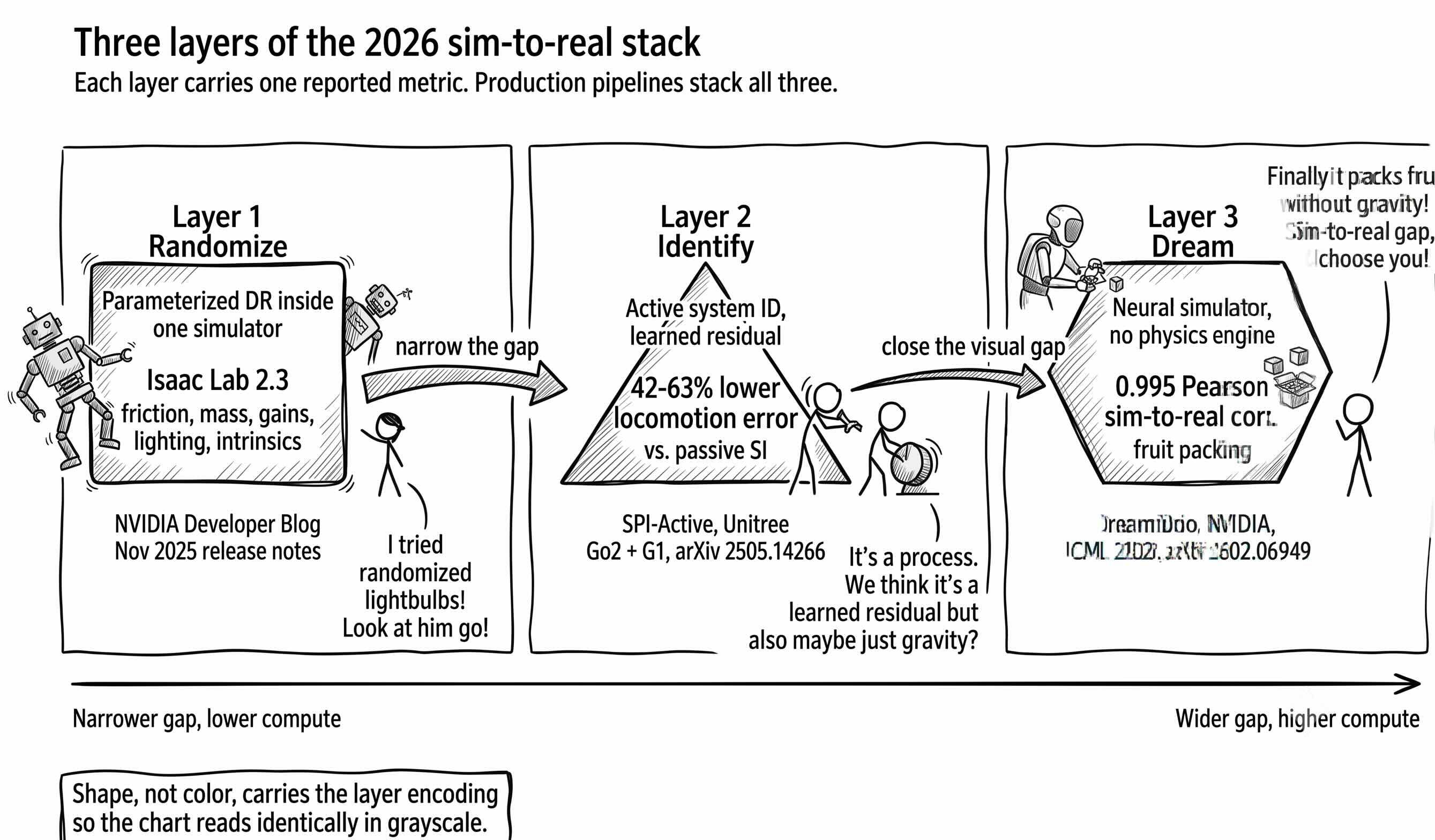
The visualization lines up the three layers of the 2026 sim-to-real stack on one horizontal axis. Layer 1: parameterized domain randomization inside a single simulator, the cheap baseline. Layer 2: targeted system identification with a learned residual, the precision step. Layer 3: the neural-simulator escape, where the simulator is no longer a hand-coded physics engine. The three layers are complements, not substitutes. The 2026 production humanoid stack is layered randomization plus a few minutes of identification plus, where the visual gap dominates, a neural renderer or world-model anchor on top.
A quieter takeaway. Training inside a neural simulator like DreamDojo is much more compute-expensive than training in a parameterized physics engine. The advantage is real, paid in GPU-hours. Until a non-NVIDIA lab independently replicates the 0.995 correlation, the honest framing is that DreamDojo is a credible bet, not a settled result.
The next question is what kind of policy gets trained on top of all this. A monolithic single-network controller, or a layered architecture where a slow vision-language reasoner thinks about the goal and a fast actor handles the joint targets. That is the fight every humanoid stack is converging into, and tomorrow’s issue walks the specific mechanism the production frontier seems to be locking in.
Subscribe for tomorrow’s read, we’re walking the robotics supply chain from atoms to algorithms, one weekday at a time.
Sources:
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos (arXiv 2602.06949)
PolySim: Bridging the Sim-to-Real Gap for Humanoid Control (arXiv 2510.01708)
Sampling-Based System Identification with Active Exploration (arXiv 2505.14266)
NVIDIA Cosmos World Foundation Models, GTC 2026 release (NVIDIA Newsroom)