
The Inner Loop, Solve or Predict
Monday, June 1, 2026 · Learning

Two demos shipped inside the same month, and they answer the same control question two opposite ways. Boston Dynamics shows an electric Atlas on a Hyundai factory floor lifting a fifty-kilogram washing machine while its torso counterweights the load in real time. Beneath the demo, a classical controller called model predictive control is solving a small optimization problem every few milliseconds against a mathematical model of the robot’s body. Figure releases Helix 02 and tells the world that 109,504 lines of hand-engineered C++ have been deleted from the inner loop and replaced by a 10-million-parameter neural network running 1000 times a second. Two stacks, one control problem. One solves for the next torque. The other predicts it.
Last week’s series closed on the filter that lets a walking robot trust its own feet. The filter answers “where am I.” The control loop sits underneath it and answers a harder question: “what should I do next.” That question has had a clean technical answer for thirty years, and as of this spring it is being challenged in a way that matters for how robots get built, where the money flows, and which companies have a moat.
How it actually works
Picture the robot’s body as a problem in physics. Joints have positions and velocities, the torso has a pose, the feet are either in contact with the floor or not, and gravity is pulling on everything. The control loop runs hundreds or thousands of times a second and at every tick it has to decide what current to send to each motor.
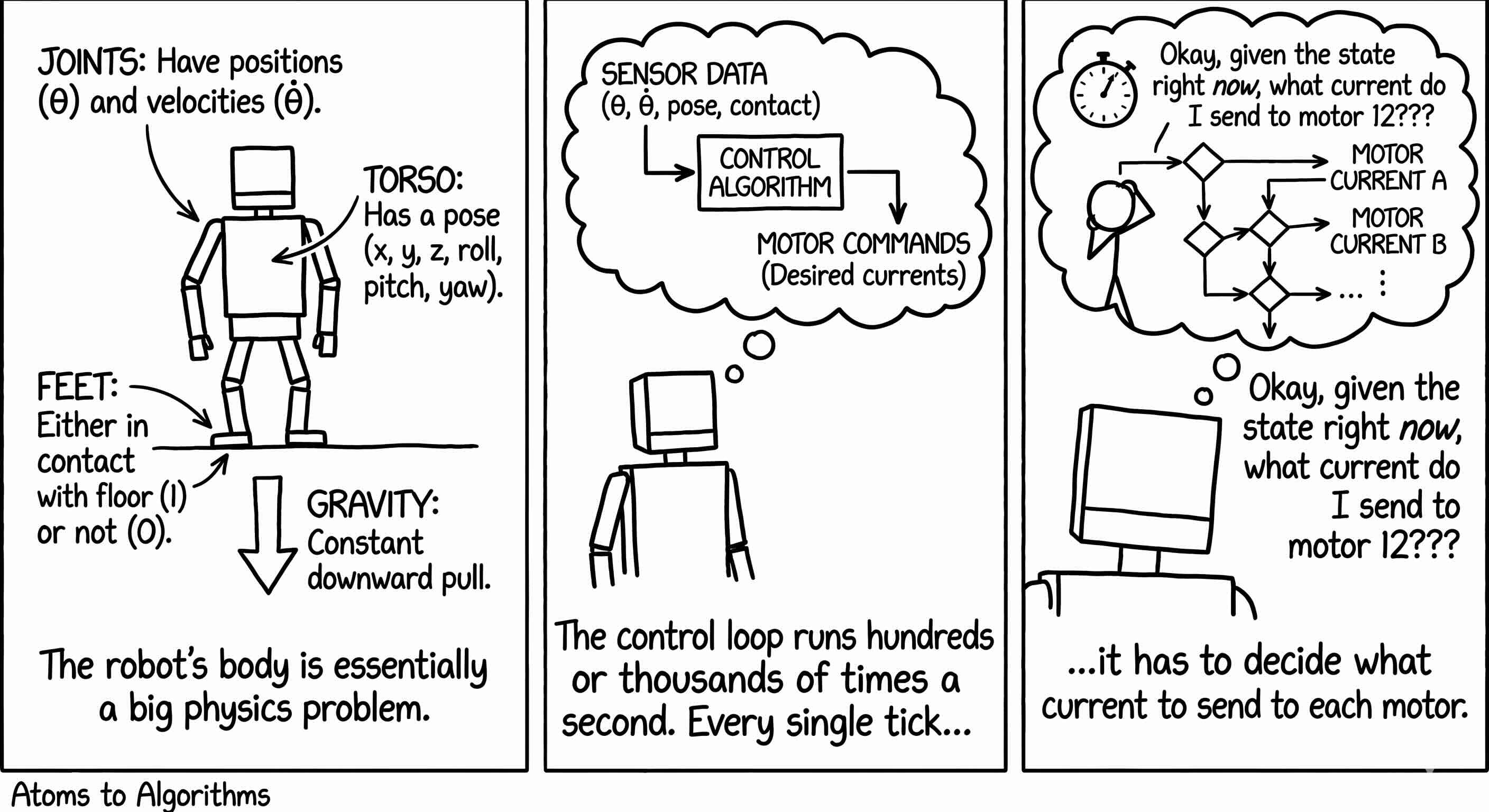
The classical answer is called model predictive control. The controller carries a mathematical model of the robot, the same one engineers write down on a whiteboard. At each tick it asks: given my model, what sequence of motor commands over the next tenth of a second would keep me upright, move my hand where it needs to go, and respect the limits of every joint and motor? It writes that question as an optimization problem, solves it, applies the first command of the answer, and throws away the rest. Then the next tick comes and it solves it again. This is what is sitting underneath Atlas when it lifts a washing machine. It is also what NASA flies on its rovers, what surgical robots use under FDA supervision, and what most industrial arms have used for decades. It reads like classic AI solution straight out of doctor strange book.
The new answer is a neural network. Instead of solving an optimization problem at every tick, the controller is a single forward pass through a small network. State goes in, action comes out. The work was done at training time, when the network watched millions of simulated rollouts in a video-game-quality physics engine and learned, by trial and error, what command to issue in each situation. By deployment, the optimization is gone. The network just maps inputs to outputs. NVIDIA’s HOVER, a 1.5-million-parameter network that controls a full-body humanoid in any of several modes, is the canonical academic version. Figure’s Helix 02 is the production version, with a 10-million-parameter “motion prior” running at 1000 Hz under a 200 Hz vision-and-touch-to-action policy. I am sure Sunday robots is doing something similar. There are interesting projects in work by other startups where they are cleaning the home for free to record the data of the cleaner what actions they are performing and using that as training data.
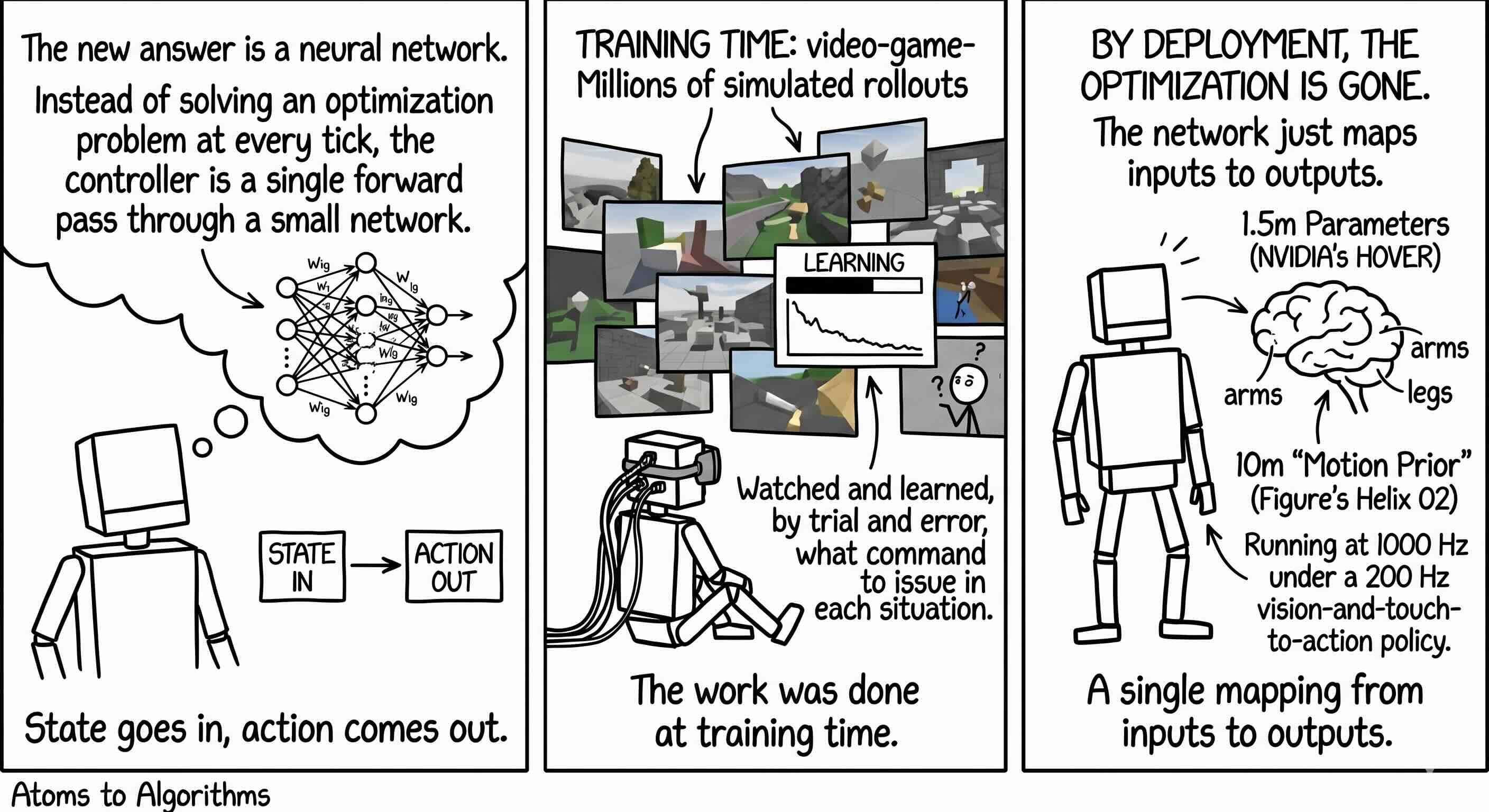
The trade-off is clean. Model predictive control gives you explicit constraints (it will not violate joint limits or friction physics within its model), it is interpretable (you can read the optimization problem), and it breaks when the model is wrong. A neural policy is cheap to evaluate (a forward pass is microseconds), it generalizes from data so it can handle situations no engineer wrote a model for, and it breaks outside the training distribution in ways that are hard to predict and harder to certify. NVIDIA’s Jim Fan, who runs the GEAR research group, has been calling this “the architectural fight of 2026” in public talks. The honest answer in late spring is that both architectures are shipping in production at the same time, and the most credible humanoid pipelines run hybrids. Boston Dynamics’ Atlas uses an MPC for balance and reaching, with a policy on top that picks what to do; Figure runs policy almost everywhere but acknowledges the regulated tasks are harder. This is more recent development where same is comparable in AI responses as well, where lot of people questioning if its capable of learning and coming up new ways or we are limited on intelligence based on data its trained on.
New this week
Boston Dynamics published the update of Atlas working alongside Toyota Research Institute’s Large Behavior Models, with all 2026 production units committed to Hyundai’s Robotics Metaplant Application Center and Google DeepMind.
Figure released Helix 02 in February, then shipped a follow-up “Scaling Helix” logistics post in May. The dishwasher demonstration, a Figure 03 unit completing 61 sequential manipulation actions in four minutes without a reset, has become the canonical “policy can do this” reference.
A paper from April, “Reference-Free Sampling-Based Model Predictive Control,” shows that the classical optimization side is not standing still. The new controller runs the same way across a quadruped and a humanoid without retraining and uses a diffusion-style schedule to explore action sequences in parallel on a GPU.
What to notice
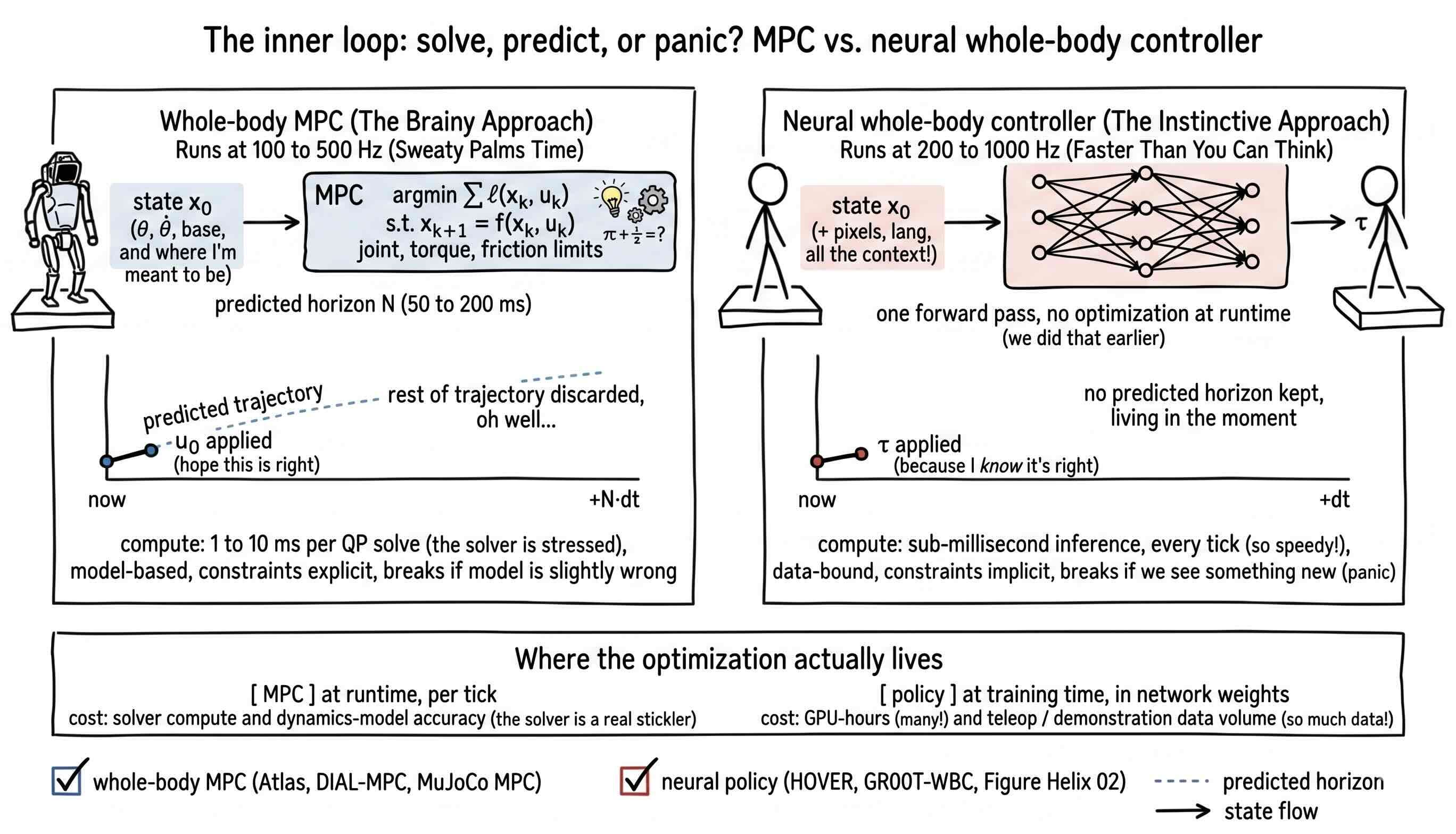
The visualization places the two inner loops side by side at the same cadence. On the left, the model predictive controller unrolls a short prediction of the robot’s future, picks the best action sequence, applies the first action, and starts over. On the right, the neural policy runs one forward pass, outputs an action, and starts over. The bottom of the figure labels where the optimization happens. In the MPC case it happens at runtime, every tick, paid for in milliseconds of compute. In the policy case it happens once, at training time, paid for in GPU-hours and data. That is the architectural fight in one picture.
The cliffhanger here is the data pipeline. The policy side wins only if you can train it, and training a whole-body controller needs roughly the same kind of data Atlas collects through teleoperation, except a lot more of it. NVIDIA’s Jim Fan describes the practical ceiling as roughly three hours of usable teleoperation per robot per day, far below what a foundation model needs. The proposed escape route is a class of wearable devices that put the robot’s gripper on a human hand and let the robot stay home: the Universal Manipulation Interface and its dexterous variant DexUMI. Tomorrow we open that pipeline and look at whether wearable data can actually replace teleoperation at the volume the policy side needs. If it can, the architectural fight tilts toward the network. If it cannot, the optimizer keeps its seat.
Subscribe for tomorrow’s read, we’re walking the robotics supply chain from atoms to algorithms, one weekday at a time.
Sources:
Whole-Body Model-Predictive Control of Legged Robots with MuJoCo (arXiv 2503.04613)
Reference-Free Sampling-Based Model Predictive Control (arXiv 2511.19204)
HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots (arXiv 2410.21229)
Large Behavior Models and Atlas Find New Footing (Boston Dynamics blog)
Streamline Robot Learning with Whole-Body Control in NVIDIA Isaac Lab 2.3 (NVIDIA Developer Blog)