
Slow Token, Fast Action
Thursday, June 4, 2026 · Learning

Figure’s Helix 02 ran an 8-hour autonomous shift at a Brookfield residential site in May with a stack that, written down, looks almost insulting in its simplicity. A 7-billion-parameter vision-language model in the head asks itself ten times a second what the scene contains and what the human is asking for, and emits a single dense intent vector. An 80-million-parameter network reads that vector and the current camera frames and decides on the next joint targets twenty times faster than the first network can think. A third network, ten million parameters at a thousand hertz, is the only thing keeping the robot upright. Three networks at three speeds is the dominant humanoid control architecture of 2026.
This week walked the path from research policy to deployed robot. Monday separated the inner-loop fight between classical model-predictive control and end-to-end neural policies. Tuesday gave the neural side a data-scaling argument. Wednesday explained the sim-to-real machinery that puts those policies on hardware. Today is one floor up: the policy itself is no longer a single network. It is a hierarchy. And the shape of that hierarchy is suddenly the hottest argument in robotics research.
How it actually works
The split has a clean justification once you see it. The slow tier handles language and long-horizon context: “clear the table, the cup is on the left, the bowl has milk in it, do not knock it over.” That work needs a pretrained vision-language model, a billion-plus-parameter transformer with tens-to-hundreds of milliseconds of latency. The fast tier handles the next half-second of motion, every five to ten milliseconds, faster than a humanoid arm can drift. The big model cannot meet that latency. A small, fast network can.
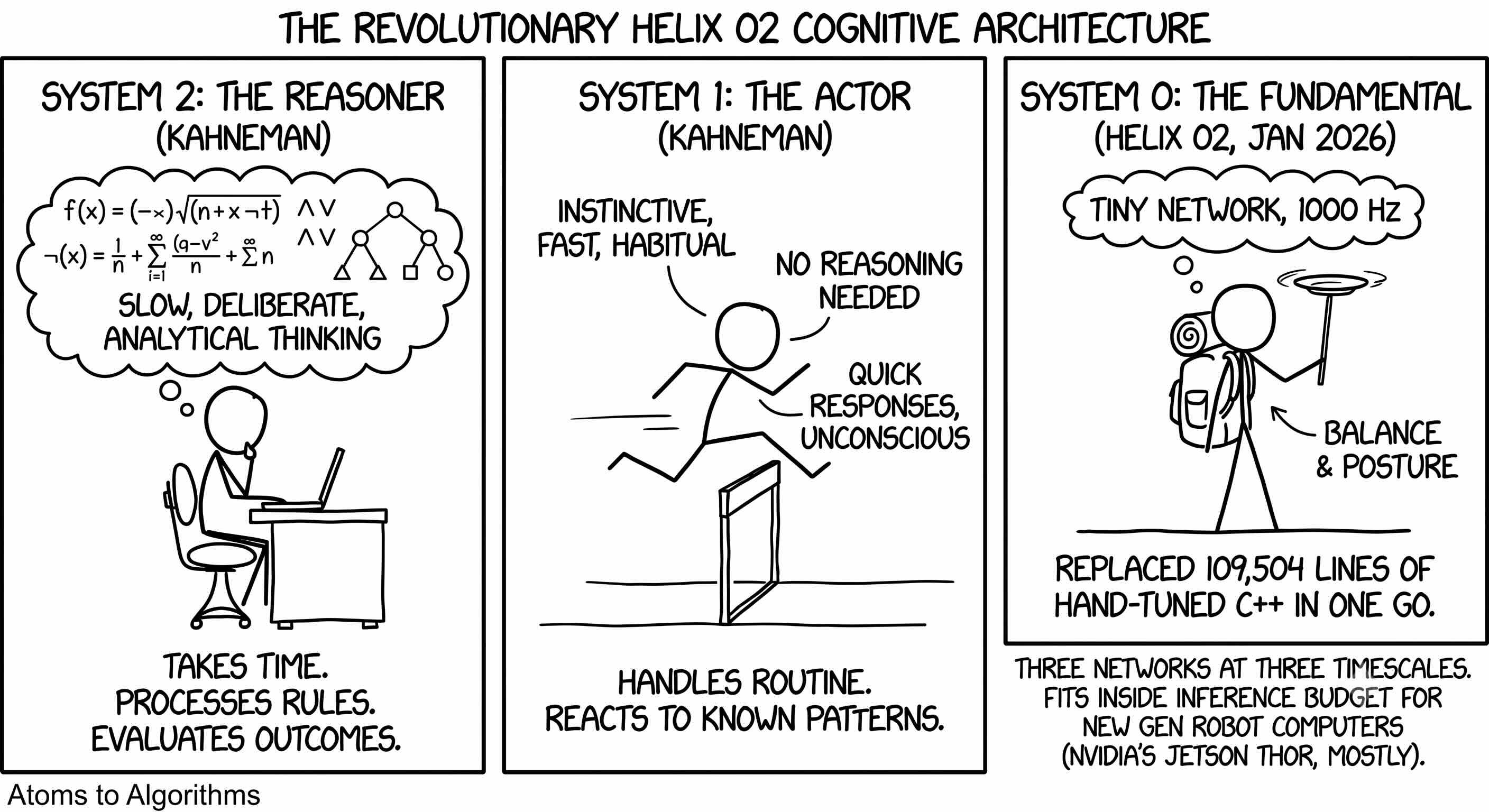
Figure names this split System 1 and System 2, borrowing Kahneman’s language for human cognition. System 2 reasons; System 1 acts. The Helix 02 release in January 2026 added System 0 below them, a tiny network at a thousand hertz to handle balance and posture. That third layer replaced 109,504 lines of hand-tuned C++ in one go. Three networks at three timescales fit inside an inference budget the new generation of robot computers (NVIDIA’s Jetson Thor, mostly) is built to handle.
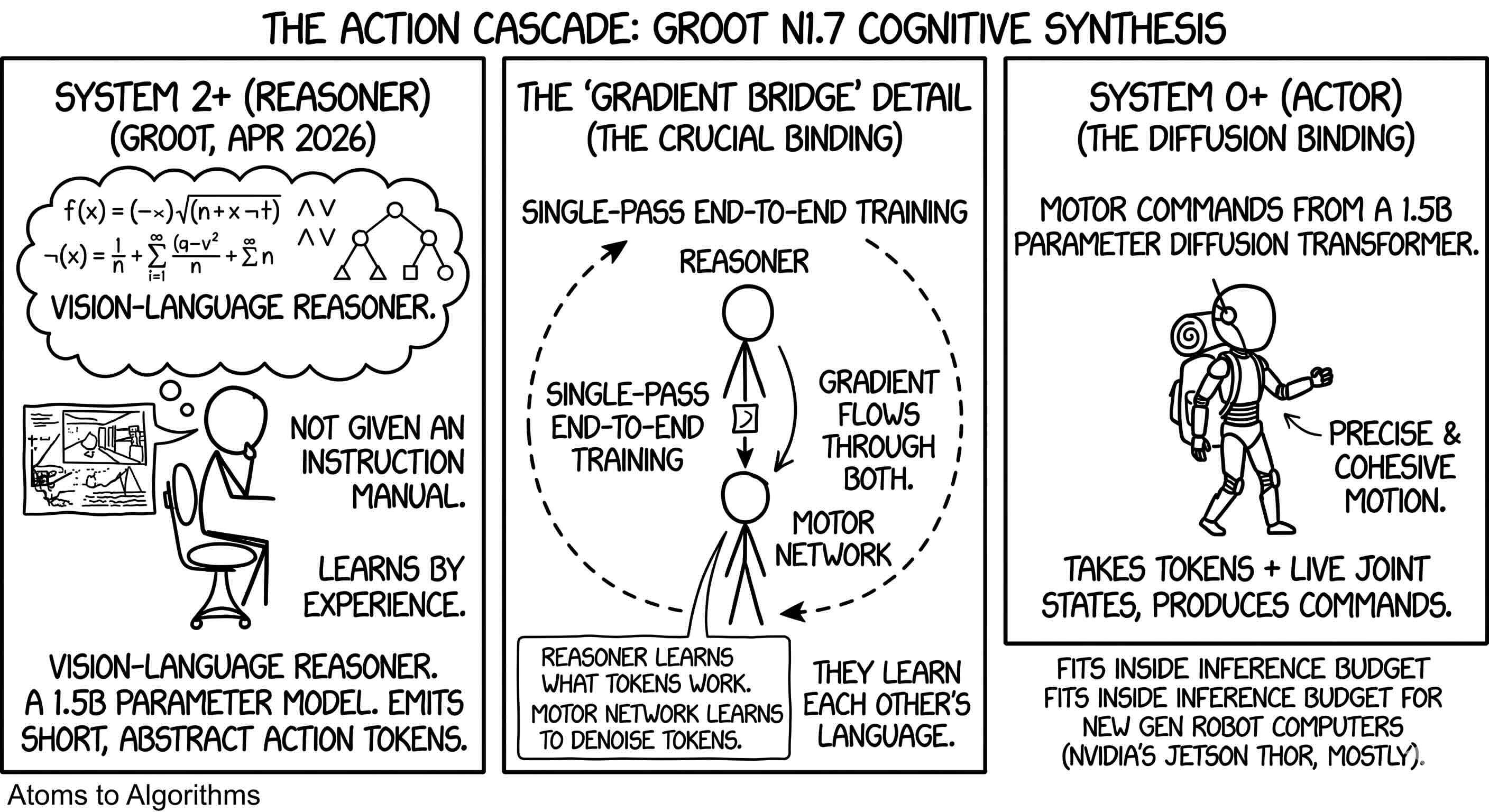
NVIDIA calls almost the same idea an Action Cascade. The GR00T N1.7 release in April 2026 ships a 3-billion-parameter model in two halves: a vision-language reasoner that emits short, abstract action tokens, and a diffusion transformer that takes those tokens plus live joint states and produces motor commands. The two halves are trained together, in one pass, with the gradient flowing through both. That detail matters. The reasoner is not handed an instruction manual; it learns what abstract tokens the motor network can carry out, and the motor network learns to denoise the tokens the reasoner tends to emit. They learn each other’s language.
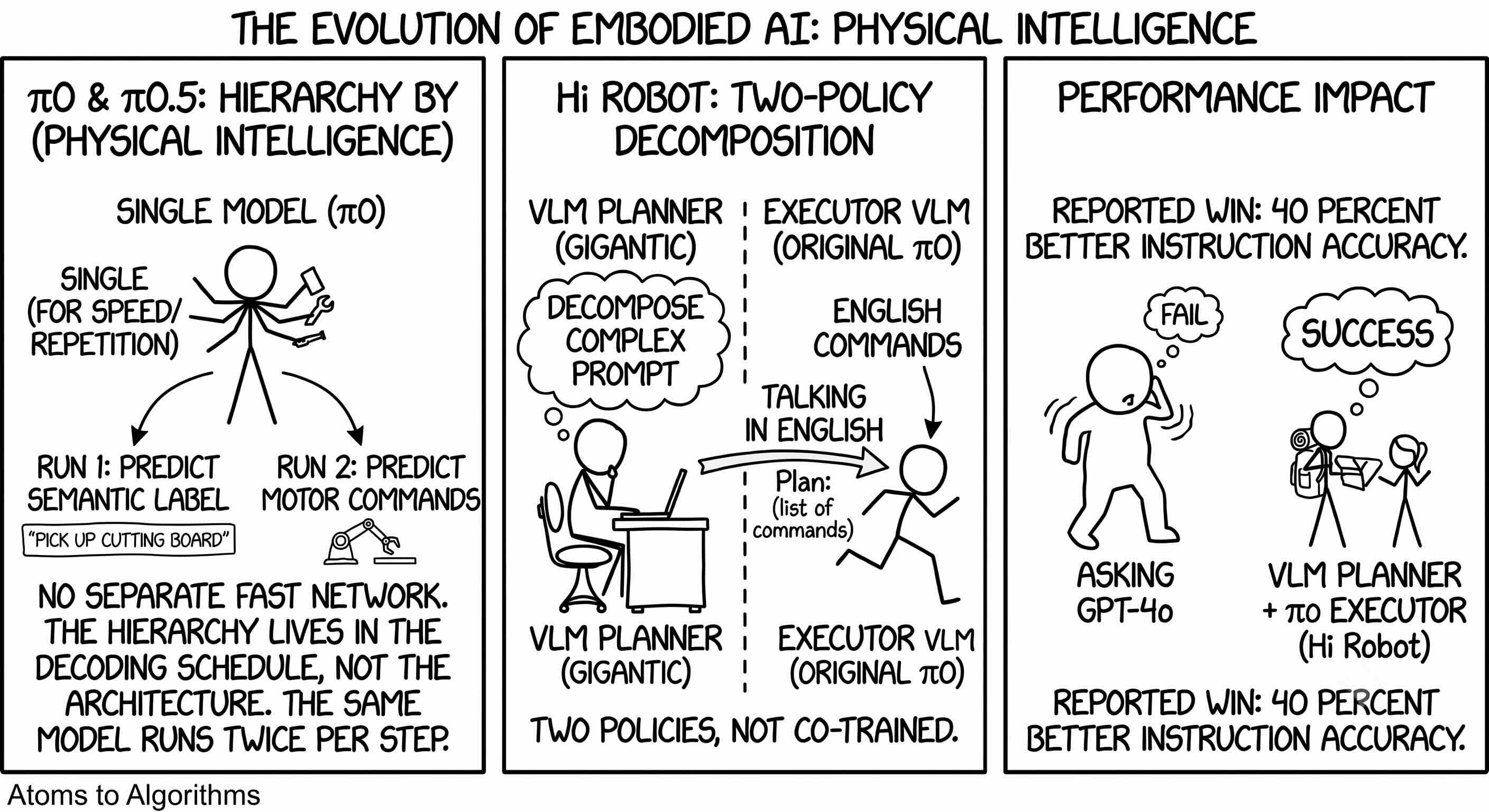
Physical Intelligence, the startup behind π0 and π0.5, takes a softer version of the same idea. There is no separate fast network. The same model runs twice per step: once to predict a semantic subtask label (”pick up the cutting board”), then again to predict the actual motor commands conditioned on that label. The hierarchy lives in the decoding schedule, not the architecture. The same lab also shipped Hi Robot, which goes the other way: a separate planner VLM that decomposes a complex prompt into English commands, fed into the original π0 as the executor. Two policies, not co-trained, talking in English. Reported win: 40 percent better instruction accuracy than asking GPT-4o to do the whole task. (now they have even better option with other models above GTP-4o)
So there are three camps. End-to-end co-training, where the boundary is an implementation detail of one model. Soft hierarchy, where the boundary lives inside one network’s decoding pass. Hard modular hierarchy, where two networks talk in plain English. A new April 2026 paper, Libra-VLA, reframes the argument as a tuning problem: performance follows an inverted-U on action-decomposition granularity, peaking at a specific middle point. Too much abstraction at the top and the bottom cannot ground the intent. Too little and the top has no work to do.
And the counter-argument worth naming: Toyota Research Institute’s Large Behavior Models are monolithic. One network, one timescale, one action chunk every 1.6 seconds. TRI’s bet is that the diffusion process itself absorbs the multi-timescale structure (early denoising steps look like planning, late steps look like refining) and that forcing the split into the architecture is premature. The headline result is 80 percent less data to learn new tasks. That is the evidence the dual-system camp has to answer.
New this week
NVIDIA released GR00T N1.7 in April as an open, commercially licensed humanoid foundation model. The bundle now spans the training environment, the model weights, the dual-system architecture, and the deployment silicon. Three robots are validated out of the box: Unitree G1, AGIBot Genie-1, Bimanual YAM. (Hugging Face announcement)
Figure’s Helix 02 humanoids completed full 8-hour autonomous shifts at Brookfield residential properties in May, with no human-in-the-loop intervention. That is the first public production-environment validation of the System 0 / 1 / 2 architecture at the duty cycle the entire labor-substitution thesis assumes. (Figure, Tech Times coverage)
Libra-VLA was accepted to ACL 2026 with the inverted-U finding on action decomposition granularity. It is the first empirical handle on where the System 1 / System 2 boundary should actually sit, rather than which side wins. (arXiv 2604.24921)
What to notice
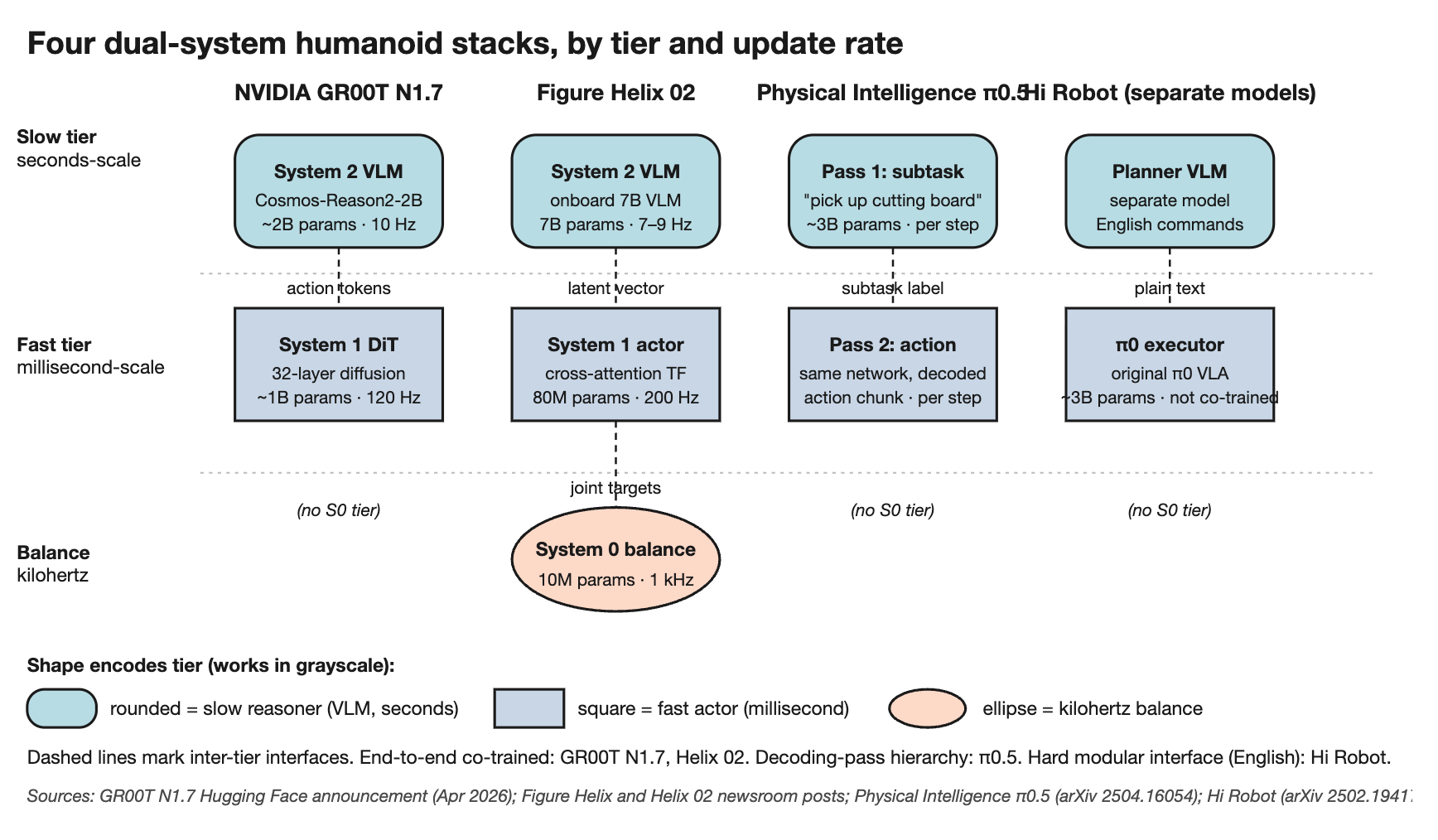
The visualization lines up four dual-system stacks (GR00T N1.7, Figure Helix 02, π0.5, Hi Robot) side by side. Each network is drawn as a labeled box scaled to its rough parameter count and positioned by update rate, from slow seconds-scale reasoning on the left to kilohertz balance on the right. The takeaway: parameter budgets and update rates per tier are converging across very different labs. 1 to 7 billion parameters for the slow reasoner. 10 to 100 million for the fast actor. Single-digit millions for any layer beneath. Designs that looked very different on the slide deck are starting to look similar on the diagram.
For most of the last decade, the question for robot policies was whether learned networks could do anything useful on a real robot at all. That question is now settled, and a new one has taken its place: how should the network be carved up? Almost everyone is converging on the same broad shape, slow reasoner on top and fast actor below, and almost everyone disagrees about the seam between them. The cascade camp thinks the seam is the load-bearing design choice and should be trained end-to-end. The monolithic camp thinks the seam is an artifact of the wrong abstraction layer and that one network can do both jobs if the diffusion process is allowed to partition itself. The head-to-head benchmarks are weeks, not years, away.
The actual seam in shipping systems today is a short stream of numbers: a latent vector or a list of discrete action tokens that the reasoner emits and the actor reads. Tomorrow’s piece is about that interface and the three candidates for becoming the cross-embodiment standard. A single action vocabulary could let one slow reasoner drive ten different robot hands without retraining the actor side. It is the closest thing robotics has right now to the question, “what should the API between language and action actually look like.”
Subscribe for tomorrow’s read, we’re walking the robotics supply chain from atoms to algorithms, one weekday at a time.
Sources: